




 Editor’s Note: As of January 2022, iland is now 11:11 Systems, a managed infrastructure solutions provider at the forefront of cloud, connectivity, and security. As a legacy iland.com blog post, this article likely contains information that is no longer relevant. For the most up-to-date product information and resources, or if you have further questions, please refer to the 11:11 Systems Success Center or contact us directly.
Editor’s Note: As of January 2022, iland is now 11:11 Systems, a managed infrastructure solutions provider at the forefront of cloud, connectivity, and security. As a legacy iland.com blog post, this article likely contains information that is no longer relevant. For the most up-to-date product information and resources, or if you have further questions, please refer to the 11:11 Systems Success Center or contact us directly.
Let’s face it, network breaches, security vulnerabilities, and the bad actors responsible for data loss are garnering all the headlines in most IT publications. With infinite budgets, we’d all have the latest networking and security gear to protect our infrastructure from any imaginable attack vector. In this same imaginary world, our network admins would be sipping cocktails on a beach somewhere. Instead, you’re reading this article about how best to protect your data while your entire IT organization is losing sleep on a nightly basis.
In 2018, we need to make one simple assumption: if your organization is not protecting your data, there’s a high likelihood that it will be lost. Infrastructure sprawl, cloud adoption, SaaS BYOD, and the increased demand for IT resiliency have made it extremely difficult to come up with a bulletproof network design. So, considering this potential, you had better have the ability to recover your data if it gets compromised.
Are you backing up your virtual environment? If so, that’s just the start. If not, please contact 11:11 Systems so that we can assist. Have you implemented a disaster recovery strategy? If you answered “yes” to both of these questions, you’re in the minority, and we’d actually like to talk to you too because we love unicorns — especially if these unicorns follow all the best practices, test accordingly, and have verified data recoverability and system restoration.
At 11:11, we recently partnered with Veeam to put together a survey that asks these questions and many more. The results are really interesting, and we’d encourage you to check out the report.
So what did we find? Not all organizations have implemented a sound backup strategy. Not all organizations are replicating workloads to the cloud. Not all organizations are doing both. And, most importantly, not all organizations are following best practices around backup and disaster recovery. Let’s discuss the best strategies for both so you can make sure you’re doing all that you can to protect your environments.
Backup Best Practices
We love hammering the following message home: Backup is as easy as 3-2-1. There’s a common rule in the industry around the best, most resilient backup methodology. This is the 3-2-1 rule. Put simply, you need 3 copies of your data: 2 of them can be stored locally on different types of media (one removable), and the final 1 is an off-site copy with a cloud service provider like 11:11.
Now that you understand the rules, the next consideration is frequency of backups. You may have retention and backup requirements unique to your organization, but at a minimum, you should be doing backups of your critical workloads every 24 hours. If you can backup key systems more often, even better!
The last thing to consider is your testing process. You should verify recoverability and data consistency across all three copies of your data. If you’ve implemented the 3-2-1 rule correctly, 2 copies of your data are air-gapped – check those too! It’s considered best practice to test this recovery process once per quarter.
By the way, we have a great checklist for you to follow. Get it, know it, use it!
Disaster Recovery Best Practices
Backup is only the start. You need to have a verified disaster recovery plan (DR) in place, too. Data recovery from a backup perspective is intended to be done locally. But, what if there is no local environment to restore to? In this case, you’ll want to augment your backup practices with a cloud-based disaster recovery site.
While DR doesn’t have a catchy little rule to abide by, there are a few terms and considerations that you’ll want to be cognizant of. We’ve listed a few of the important ones below:
RPO (Recovery Point Objective) – This is a time measurement going backward to describe how old your data is at time of failover to the cloud. Most organizations can tolerate no less than a four-hour RPO, while 15 minutes or less is quickly becoming optimal. When assessing DRaaS providers, be sure they can meet the objective you’ve set forth for your organization.
RTO (Recovery Time Objective) – This is also a time measurement, but this one looks forward to the amount of time it takes to spin up your environment in the cloud. Companies that are familiar with legacy DR solutions are typically comfortable with a 24-hour RTO. Those days are gone, and significant advancements in software-based DR solutions have dramatically reduced the average RTO. A good rule of thumb to consider when evaluating RTO is roughly one minute per virtual machine.
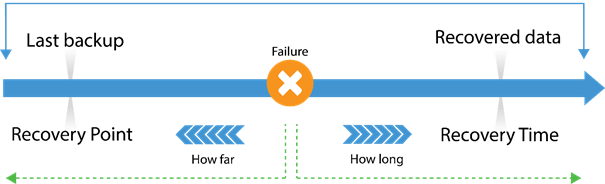
Image borrowed from Veeam.com
Storage Agnostic – When evaluating a DRaaS solution, you no longer need to maintain parity between the storage vendor you leverage in production and the storage you consume at the DR location. Be sure the DRaaS provider you consider leverages enterprise-class storage with multiple tiers that will meet your I/O demands at the time of failover. In addition, make sure your data is encrypted at rest and in transit.
Workload Prioritization – It would make no sense to move large amounts of data over to a DR location without an understanding of the priority levels of your applications. Your most mission-critical workloads need to take precedence and spin up first at the time of disaster. Make sure the DRaaS provider you choose has the ability to execute failover plans and runbooks according to your business needs.
Automation / Orchestration – Why do all the heavy lifting yourself? In today’s landscape, there are no longer 38 different hoops that you need to jump through at the time of failover. Back in the day, moving data from point A to point B was “good enough.” Now, you’re going to want a solution that automates everything for a seamless failover experience.
Console Visibility – In the event of a failover, you will have to become familiar with a new environment from which to manage your workloads. Mass-market clouds require not only a hypervisor conversion process but come with a steep learning curve when it comes to successfully working with applications in that environment. It’s considered best practice to, as closely as possible, mimic your on-premises environment in terms of hypervisor, backup capabilities, security tools, networking integration, and overall access. What better way to achieve that than through an integrated console that has the same look and feel as in production?
Testing & Failback – Two often-overlooked considerations to keep in mind are testing and failback ability. Any solution that you decide on should be able to be tested frequently. At a minimum, it’s considered best practice to test once a quarter. With advancements in software-based DR solutions, on-demand testing is now commonplace. Also, be sure to choose a solution that has an integrated failback mechanism. What good is it to be “stuck” in the DR location with a very cumbersome process to get your data back? At that point, you’re essentially now a customer of that provider.
These are just a few things to keep in mind when evaluating a DRaaS provider. As mentioned previously, here is the checklist for data protection best practices.
Hopefully, the report, the checklist, and this post itself have shed a little light on the state of data protection in 2018. To summarize: security is not enough; you need a proven backup and disaster recovery solution in place when the inevitable occurs.





