





Date: July 6, 2017
Author: Mike Mosley
Editor’s Note: As of January 2022, iland is now 11:11 Systems, a managed infrastructure solutions provider at the forefront of cloud, connectivity, and security. As a legacy iland.com blog post, this article likely contains information that is no longer relevant. For the most up-to-date product information and resources, or if you have further questions, please refer to the 11:11 Systems Success Center or contact us directly.
In this post, we will go over some of the options and considerations when creating a replica job to a Veeam Cloud Service Provider. A replication job’s settings can be changed, and VMs included in a job can be removed or added at any time. However, it is a good idea to have a replication strategy in mind when creating jobs.
VM Grouping Considerations
Typically, the first option to consider when creating a job is what servers you would like to add. Many users have debated the best setup for grouping servers: one large job with all VMs, one VM per job, or somewhere in between.
There is no definitive answer or best practice that applies to all customers. At the end of the day, if you have 10 servers that need to be replicated, you can use one job that might run for five hours or 10 jobs that each run for 30 minutes. I recommend grouping servers based on size and rate of change. If you have several small servers, or servers with minimal change, you may want to group those together while separating larger or more dynamic servers. Typically, large servers with a lot of daily change will take longer to replicate. If you place those in their own job, you won’t have smaller VMs sitting idle during that job window.
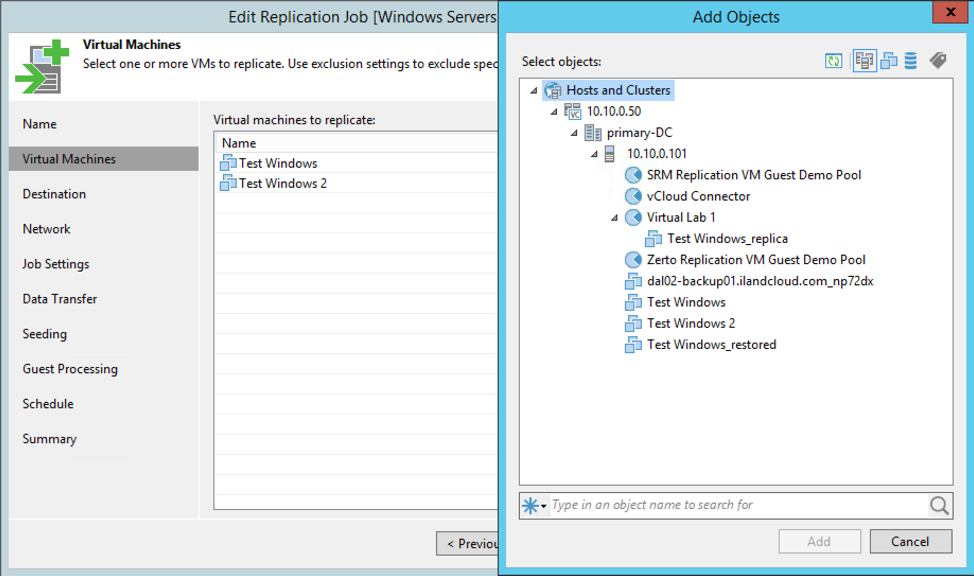
Adding VMs to a Veeam replica job
You may also have different retention requirements or RPO requirements for certain servers. For non-critical or less-utilized servers, you may only want to replicate once a day or once every other day. Other, more critical servers need shorter RPOs that you may want to run every four hours or so. In that case, you will need to separate these VMs into jobs that run more often. The retention settings are global for a job, so you might split servers into a job with 14 days’ retention and less critical servers in a job with seven days retention. You will always be able to change the job settings or move VMs from one job to another, but having retention, RPO and scheduling goals in mind will help when determining how to group your servers in a job.
Replica Source Considerations
Another consideration when adding servers to a replica job is the source for replication. Typically, Veeam will replicate the actual source server by creating a snapshot of the VM and replicating from the source VM’s disk. However, you may also have backups that run periodically on this server or local replica jobs that are also taking snapshots of this server. To reduce the number of snapshots, you can choose to use a backup file as a source for replication. With this method, Veeam reads the data of the latest backup for a VM and then replicates this data to the target server at 11:!1 Systems. This process allows for replication of a server without having to run a snapshot of the production VM. However, the replication relies on the backup information, so you will need to ensure the backup jobs complete successfully and on time. If the replica job starts while the backup is still running or if the backup job has not created a new restore point, the replica job may fail. So, you will need to make sure the scheduling is set correctly so that a new backup is created every day for replication.
Keep in mind that the data replicated will be the data that was saved in the actual backup. If your backup job runs at 8:00 a.m. and then the replication starts at 8:00 p.m., you will only be replicating the data from that 8:00 a.m. backup job. That leaves a 12-hour gap in time where data has not been replicated. So, you may want to run your replica as soon as the backup job completes. For more information on replicating from a local backup file, please visit the Veeam help center.
Storage Usage Considerations
One final consideration is the storage used by servers, as well as the storage consumed for retention. If you are replicating 10 servers that have 1,500GB of total used data, you may think that you only need 1,500GB of available storage on the target site. However, keep in mind that your servers may grow overtime. A file server may be configured with 500GB of disk storage but only use about 300GB of that. However a year from now, that 500GB disk may be full and need another 500GB disk. As this storage consumed grows in your production environment, it will also take that space in your DR environment, and you may want to allocate extra storage to handle this growth. On top of the actual storage usage from the base VM, each restore point for a replica server is saved as a snapshot, which consumes space. The size of a snapshot is dependent on the amount of change throughout the day. A 300GB server that has 30GB of change will have a larger snapshot than a 500GB server with only 5GB of change.
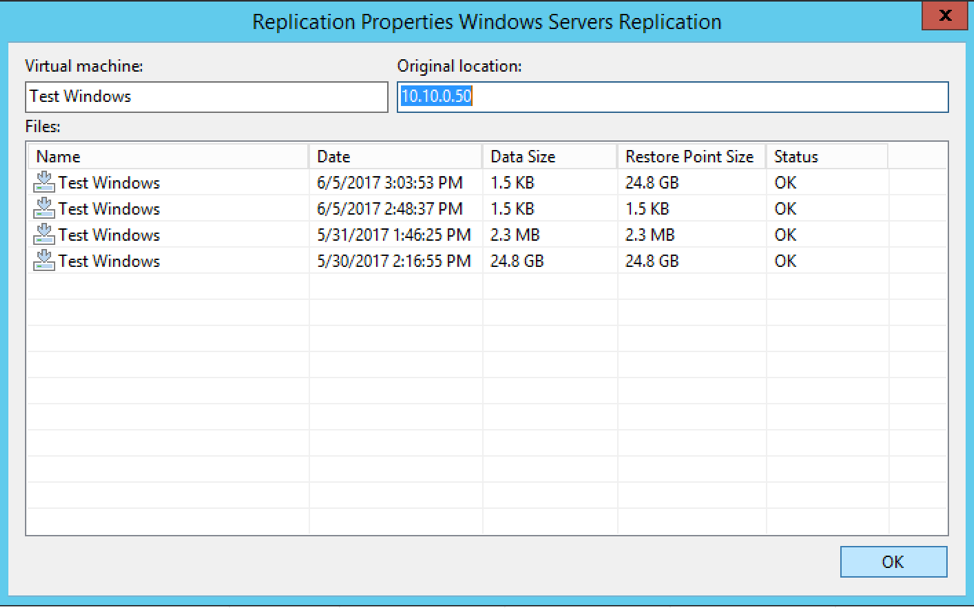
Properties of a Veeam replica server. The Data Size column shows the storage actually consumed by a restore point
Certain servers may also have more snapshots for retention purposes, which also increases the overall space consumed. For instance, let’s say we have a 500GB server in a job that runs every four hours, giving us six restore points in a 24-hour period. If we want to keep a week’s worth of retention, that would be 42 restore points for that server (six restore points a day for seven days). If our average snapshot size on this server is 1GB, that is an extra 42GB on top of the 500GB used by the base replica. Space can always be added to your environment over time, however, this is an important consideration when deciding how many restore points to keep for a server.
Once you have considered these above options and have a replication strategy in place, we will be ready to build out the replica jobs. In my next post, we will do an in-depth walk through of best practices and settings to configure for replicating to the11:11 DraaS for Veeam infrastructure.





