




Editor’s Note: As of January 2022, iland is now 11:11 Systems, a managed infrastructure solutions provider at the forefront of cloud, connectivity, and security. As a legacy iland.com blog post, this article likely contains information that is no longer relevant. For the most up-to-date product information and resources, or if you have further questions, please refer to the 11:11 Systems Success Center or contact us directly.
In the world of DRaaS, partial failovers have become a very popular topic of discussion. Essentially, customers want to know that if needed, they will be able to failover a subset of their production environment. While partial failovers are possible, there are several challenges that need to be considered ahead of time.
First, let’s clarify the difference between full and partial failovers. The fundamental goal of a DRaaS solution is to recover your production environment after a total site disaster. This includes bringing your systems back online and enabling network connectivity to the outside world or branch offices. Below is a diagram of what a standard DRaaS setup may look like between a customer’s premise site and 11:11 Systems.
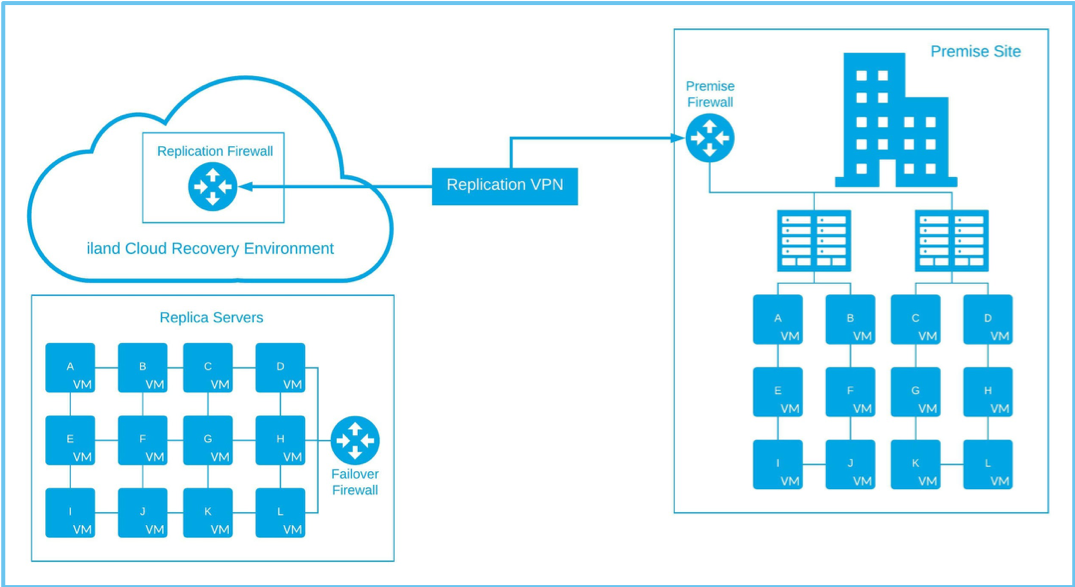
The source or premise site will replicate to 11:11 over a replication VPN tunnel to an 11:11 firewall. This replication firewall only handles replication traffic and is independent of the failover environment and failover networking. When a failover is initiated, the replica servers boot up at the 11:11 site and use the failover firewall for all network connectivity. The important thing to note in the diagram above is that there is no connectivity between the source premise servers and the replica servers. In this scenario, you should assume that the premise site is offline and connectivity is not needed. Additionally, the replica servers that boot up at 11:11 should be exact mirrors of their source counterparts, as they will have the same hostname and IP address.
The above example details the flow of a full-site failover. However, what happens if the full site is not impacted and only one server or a subset of servers need to failover? Some organizations have made requirements that they are able to granularly failover their environment. For instance, let’s change the above diagram and say that only A, B, E and F have become degraded and need to failover.
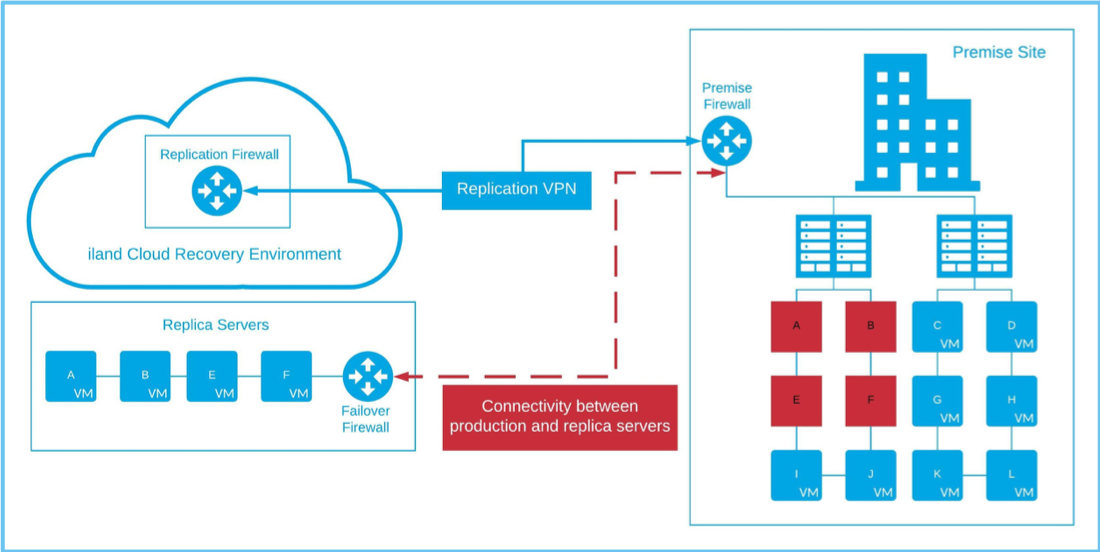
In this scenario, we are able to recover the impacted servers without having to failover the entire environment. You will notice that in the diagram below, there is a new tunnel enabling connectivity between your recovered servers and your production servers that were not affected. Here is where this whole process gets tricky, as there are several options, each having its own caveats.
Review Your Use Case for a Partial Failover
There are many reasons why an organization may want to prepare for a partial failover along with preparing for a full site emergency. You may have physical resources along with your virtual environment and want to protect yourself when only the virtual resources are impacted. Or, you may want to protect yourself from unexpected host failures or an accidental VM deletion. You might also want to review communication between your premise data center and other off-site or branch locations. You will also want to confirm if your servers are being backed up and if so how often? Are they saved locally, off-site or both?
Your goal initially should be to get a good understanding of exactly what changes or steps are needed during a partial failover. You may find that the labor needed during a partial failover scenario outweighs just restoring a server from a backup. Enabling communication for the partially failed over servers may take longer to fully configure than you are able to tolerate. Mapping out the partial failover process, including the internal or external changes needed, expected time to complete, and overall difficulty may help in figuring out an alternative method. Unfortunately, planning for a partial failover includes overcoming challenges and obstacles that are not as problematic when failing over a full environment.
Partial Failover Challenges
The main challenge with running a partial failover is enabling communication from your DR site back to production. In the above partial failover diagram, the A, B, E and F servers that failed over would need to communicate back with the other unaffected source servers. In typical DR setups, the networking at the failover site would mimic the source site. So if the “A” VM has IP address of 192.168.1.10 at the source site, it will have the same IP address after failover. This ensures that server communication and any AD/DNS configuration remains the same for your environment after a failover.
However, if the failover and production subnets are the same, you are not able to create an IPSec VPN tunnel between the sites. This is because creating a VPN between two sites using the same subnet makes routing impossible. When server A fails over with IP address 192.168.1.10 and needs to connect to server C with IP address 192.168.1.13, the firewall is unable to determine if traffic from server A should stay local or route across the VPN tunnel. Because of this confusion in the routing, the VPN tunnel will never establish or successfully pass traffic. Essentially, the simplest method to create a connection between two sites becomes impossible.
It is possible to create a VPN tunnel between the failover and production sites if they are not using the same subnets. So instead of the A server failing over with IP address 192.168.1.10 it may use something like 192.168.2.10. This would be true with all servers, so if any server fails over, it would change its IP to have a 2 in the third octet. While this allows for VPN connectivity, you then will have to account for additional caveats.
First, when server A boots up at the recovery site with its new IP address, it will have connectivity back to your Active Directory and DNS server. This means server A’s IP address will be updated in your production AD and DNS infrastructure and then replicated to remote AD/DNS servers. While this works during a live scenario, it makes testing a bit harder. With most DR solutions, you are able to test a failover without having to impact or take down any production servers. However, with this method, you could potentially have server A online at the DR site and the production site at the same time. While they would have different IP addresses, their hostnames would conflict in your AD/DNS infrastructure. What’s worse, production changes or activity from the other production server may get routed to replica server A. If you end the test, those changes will be erased and you may lose hours of production work or updates. Essentially, this method causes a much more intrusive testing or failover method and needs to be heavily analyzed before testing.
This setup also becomes complicated when determining how to configure your DR replication. Typically, you have to configure the network and IP address used by a server once it has failed over. Some solutions allow you to use a different network between a live failover and a test failover, but you are not really able to prepare for a full versus partial failover. So, if you have your replica jobs or failover environment set up for a full-site failover but a partial is needed, you may need to manually make changes before, during or after the failover. This can increase the possibility of mistakes and lengthen your failover process if it is not fully documented.
If setting up a VPN tunnel or changing IPs seems too problematic or complicated, you may want to look at alternate methods, such as public communication or a quick failover and failback. Public communication would involve setting up a public IP that NATs to one of your replica servers. So, if server A is failed over, your production servers can communicate with it over the public IP address. However, this could involve you needing to first make public DNS record changes which can take time to populate across the public network. You also may have internal scripts, applications or processes that refer to server A by IP address. If that IP address changes, this process may break. Communicating over the public internet is drastically less secure and may not be a viable option for many companies.
If you can tolerate downtime for an hour or more, you could also consider failing over and then failing back to your production environment. This can be useful if you want to protect against an accidental VM deletion or if it becomes corrupted from malware. Basically, you could fail the server over to the DR location without connectivity back to production. If you are able to confirm the data needed is on the server and uncorrupted, you could enable reverse replication and failback to your production data center. This may take longer than restoring a VM from a backup but it may have more up-to-date data available. While this method takes longer to make the data accessible, it also removes any changes or work needed to establish communication between the sites.
Looking Forward and Data Center Extension
Data center extension has become a more popular setup as it essentially creates a layer two connection between the recovery and production data centers. This overcomes the challenges with the VPN as routing is not needed in this setup. While this has been an option in the past, it has become a bit more difficult as it was usually a physical cross-connect or direct circuit installation. However, as the DR industry and providers continue to grow and innovate, virtual and appliance options are becoming available. Of course, data center extension can involve the same or unique caveats as explained above.
Partial failovers will continue to be a requirement or major concern for companies as it is important to be protected for any disaster scenario. It is important to plan, diagram and test your failover process as often as possible to ensure you are prepared for disaster. If you have any questions about your DR solution, feel free to contact 11:11 for assistance or advice on your recoverability.




