





Date: July 27, 2017
Author: Mike Mosley
Editor’s Note: As of January 2022, iland is now 11:11 Systems, a managed infrastructure solutions provider at the forefront of cloud, connectivity, and security. As a legacy iland.com blog post, this article likely contains information that is no longer relevant. For the most up-to-date product information and resources, or if you have further questions, please refer to the 11:11 Systems Success Center or contact us directly.
Now that we have setup our Veeam replication jobs and created a Veeam Failover Plan, we are ready to test our failover functionality. A failover can be initiated in two different ways depending on your failover scenario. In the event that the full environment is down, you can conduct a full failover using the Veeam Hardware Plan. Alternatively, if your data center is online with just certain servers down, you can choose to failover only the affected servers for a partial failover. Depending on which method and networking device you use, there may be differences in how you can access the replicas. Below, I will detail the differences between a full and partial failover, as well as considerations to keep in mind when performing a failover.
Full Failover Considerations
A full failover refers to any failover that is initiated with a Veeam Failover Plan. This can be confusing when you consider that you are able to conduct a failover of all replicas individually without using the failover plan. However, the use of a failover plan versus individually failing over replicas changes how the Veeam Network Extension Appliances work. In the failover plan we created earlier in this series, we configured NAT rules to allow for public RDP access to my replicas. These NAT rules will only take effect during a full failover using the Veeam Failover Plan. This is because the failover plan is meant to be used when your environment is completely down.
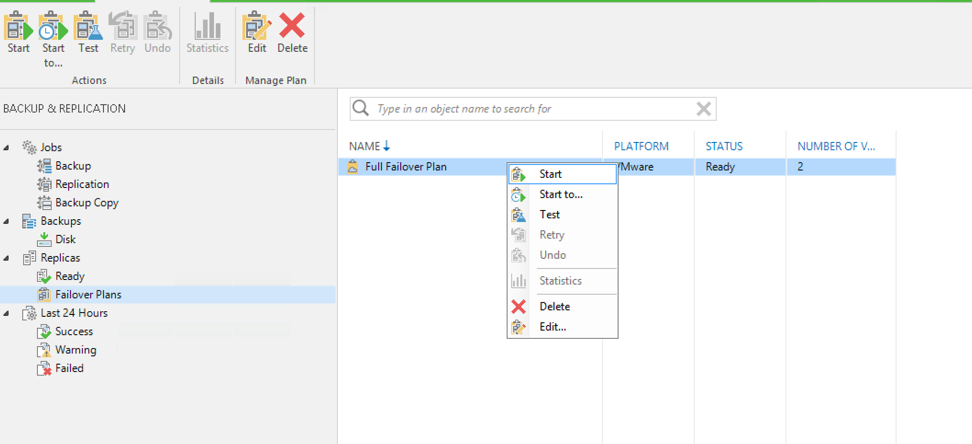
Initiating a Full Failover in the Veeam Console with a Failover Plan
Full failovers can also be initiated outside of your Veeam console. In the event that your entire data center drops offline or is destroyed in a disaster, you will also most likely lose access to your Veeam server. If you still have internet access from your location, you could login to the Veeam web portal to view and start your failover plans. This website is running on the 11:11 Cloud Backup for Veeam Cloud Connect infrastructure, and login information will be provided to your during your deployment. Please note that only failover plans will be accessible in this portal, not individual VMs. It is11:11 System’s recommendation to have at least one failover plan made that includes all replicated servers for this reason. In the event that your site is inaccessible and you are not able to access the Veeam portal you can also call the 11:11 Support team. From the provider side,11:11 is able to initiate a tenants Veeam Failover Plan in the case that all other access is down. Again, 11:11 will be able to initiate a failover plan but cannot failover individual VMs through Veeam.

Failover plan in the Veeam web console
If you are using a third-party firewall, such as the Cisco ASAv, you may not have a Veeam Network Extension Appliance in your environment. This NEA is where NAT rules from a failover plan are configured, and controls the inbound and outbound access during a failover. In these cases, you will still want to create at least one failover plan that includes all of your replicated servers. Even though you will not rely on the failover plan and Veeam NEA for network access, it still allows you to initiate a failover through the web portal or from the cloud provider side.
Another benefit of the Veeam Failover Plan is the ability to control the boot order of the included servers. Instead of manually failing over your servers in a particular order, you can set this order in the plan. You can also set boot delays for the next replica on the list. For instance, you may want to failover a domain controller or AD server first, and then delay the rest of the group. This gives your domain controller time to power on, start domain services and even reboot, if necessary, to assure it is in authoritative mode. This control and automation allows you to start a failover with just one click and then focus on any other issues, such as DNS changes for your environment.
The Veeam Failover Plan is a great tool that allows you to configure and control your failover strategy when a full-site disaster strikes. However, you may run into a situation where you only need to failover over one or more certain servers while the rest of your environment is online. This use case can be handled with a partial failover through Veeam.
Partial Failover Considerations
You may run into a situation where one server has become affected by malware or accidentally deleted or crashed and needs to be restored. However, a full-site failover is not necessary as all other systems are online. This can be easily achieved in the Veeam console by viewing the Replicas page and failing over only the problem server, or servers. In this scenario, Veeam fail overs the specified server(s), powers on the Network Extension Appliance at the recovery site, and powers on the NEA at your source site. The two NEAs create a bridge between the two sites allowing for internal communication.
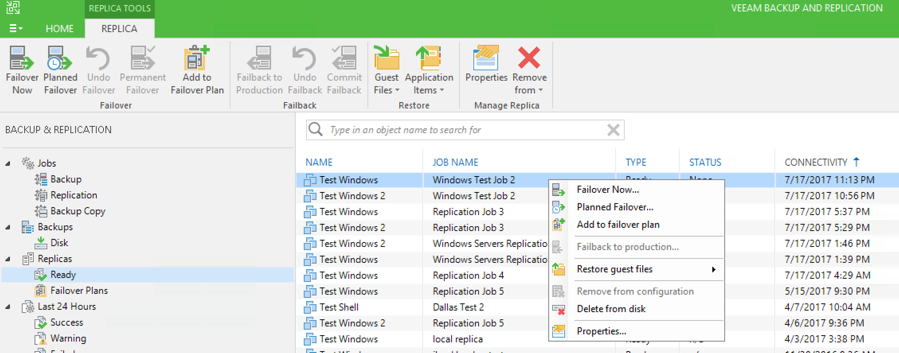
Initiating a Partial Failover in the Veeam Console
Because the NEA was not used during this failover, the NAT rules configured in the failover plan will not be in use. However, if there is any public access given to the server on the production-side firewall, that should still be in place. For instance, if you failover a web server that hosts the website example.com with a partial failover, then you should be able to access example.com once the failover is complete. There is no need to change DNS to your 11:11 IP addresses, as the NAT will continue to flow from your production firewall internally to the replica server. Because the partial failover allows internal communication between the production and recovery sites, all services and communication should work as they do during normal production operations.
Keep in mind that if you want to test out a partial failover, you may have issues if both the source and target server are online at the same time. Essentially, you would have two servers online that have the same IP address. The NEAs will prevent any kind of conflict, but there may be some confusion on whether or not you are accessing the replica server when testing. In this case, it may be best to either disconnect, power off, or change the IP of the source server. Once that is done, you can access the replica through its normal IP and ensure you are on the right server for any testing. However, this might be a process that should be done after hours or during a maintenance window.
If you are using a third-party firewall, such as the ASAv, then most likely you do not have a Veeam NEA at the recovery or source side. This makes a partial failover with that same internal communication more difficult. Because the recovery and source side will have the same subnets, this can cause an IP conflict which prevents the use of a site to site VPN tunnel. There are other methods to use, such as an SSL VPN client or configuring and using public access to reach the failed servers. Alternatively, there is a workaround that 11:11 has tested and implemented that uses both the NEA appliances from Veeam, as well as the third-party firewall. This option does allow the internal communication as mentioned above, but will require some extra set up. If you would like to ensure this NEA bridge method is available for a partial failover while using a third-party firewall, you can request for this with the 11:11 Support or Cloud Services teams.
Failback Considerations
When you have completed a live failover, whether full or partial, the next step will be to failback to your production environment. Veeam gives three options for failing servers back to your production environment. You can failback to the original VM, failback to the original VM in a different location, or failback to a specified location. The first two options allow you to use the source server as a seed. So, if the source still exists, you can replicate the changes made after the failover back to the source VM. This is typically a faster failback process as the entire server is not replicated. The last option is used for if the original source VM was completely removed. For instance, if a server is accidentally deleted and you do not have a backup, you can use this method to fully restore the server back to the production environment. This method will be longer as the full server is replicated from scratch.
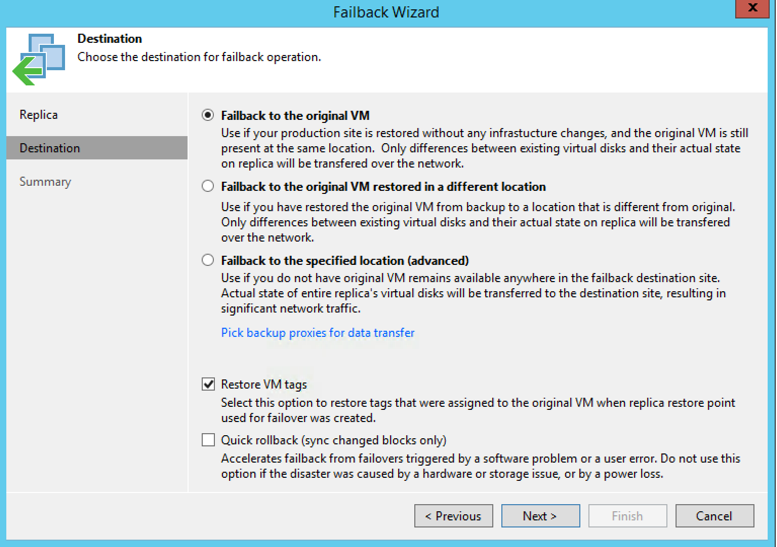
Options when choosing to Failback to the production site
One thing to keep in mind during a failback operation is that there will be some downtime. Veeam will begin the failback process by powering off the server at the 11:11 recovery site, as well as shutting down the VM at the source site if it still exists. This is to ensure that no new changes are made during the reverse replication. The actual time for the failback depends on the size of the server as well as the amount of changed data. A 500GB server that has had minimal changes might finish faster than a 200GB server that has a large amount of changed data throughout the day. Once the failback operation completes, the original source VM is powered up and the target replica at 11:11 will remain powered off and ready for normal replication. During this reverse replication and failback is also a good time to update any DNS changes that may have occurred back to their original configuration.
In the event of a live failover scenario, whether it is a partial or full failover, it is a good idea to contact the 11:11 team. Even if you have already completed the failover process, 11:11 will ensure that all communication to the servers is working as expected, and make any necessary changes, or help with any troubleshooting needed. We can also coordinate a time to walk through the failback process and ensure that production is restored at the source site.





